... while (!candidates_.empty()) { auto i = candidates_.begin(); Candidate candidate = *i; candidates_.erase(i);
// 已经优化了的--跳过 if (!IrOpcode::IsInlineeOpcode(candidate.node->opcode())) continue; // 无效死代码,跳过 if (candidate.node->IsDead()) continue;
// 预算检查--- double size_of_candidate = candidate.total_size * v8_flags.reserve_inline_budget_scale_factor; int total_size = total_inlined_bytecode_size_ + static_cast<int>(size_of_candidate); // 超过内联预算上限---本次暂时不优化 if (total_size > max_inlined_bytecode_size_cumulative_) { info_->set_could_not_inline_all_candidates(); // Try if any smaller functions are available to inline. continue; }
Reduction JSInliningHeuristic::InlineCandidate(Candidate const& candidate, bool small_function){ ... // 检查调用是否稳定--参数检查! Node* if_exception = nullptr; if (NodeProperties::IsExceptionalCall(node, &if_exception)) { Node* if_exceptions[kMaxCallPolymorphism + 1]; // 检查历史执行情况:运行稳定性、异常结果检查 for (int i = 0; i < num_calls; ++i) { if_successes[i] = graph()->NewNode(common()->IfSuccess(), calls[i]); if_exceptions[i] = graph()->NewNode(common()->IfException(), calls[i], calls[i]); } // Morph the {if_exception} projection into a join. ... }
...
// 稳定性检查通过后,逐步进行内联优化!直到总内联优化占用达到上限! for (int i = 0; i < num_calls && total_inlined_bytecode_size_ < max_inlined_bytecode_size_absolute_; ++i) { if (candidate.can_inline_function[i] && (small_function || total_inlined_bytecode_size_ < max_inlined_bytecode_size_cumulative_)) { Node* call = calls[i]; Reduction const reduction = inliner_.ReduceJSCall(call); if (reduction.Changed()) { total_inlined_bytecode_size_ += candidate.bytecode[i]->length(); call->Kill(); } } }
returnReplace(value); }
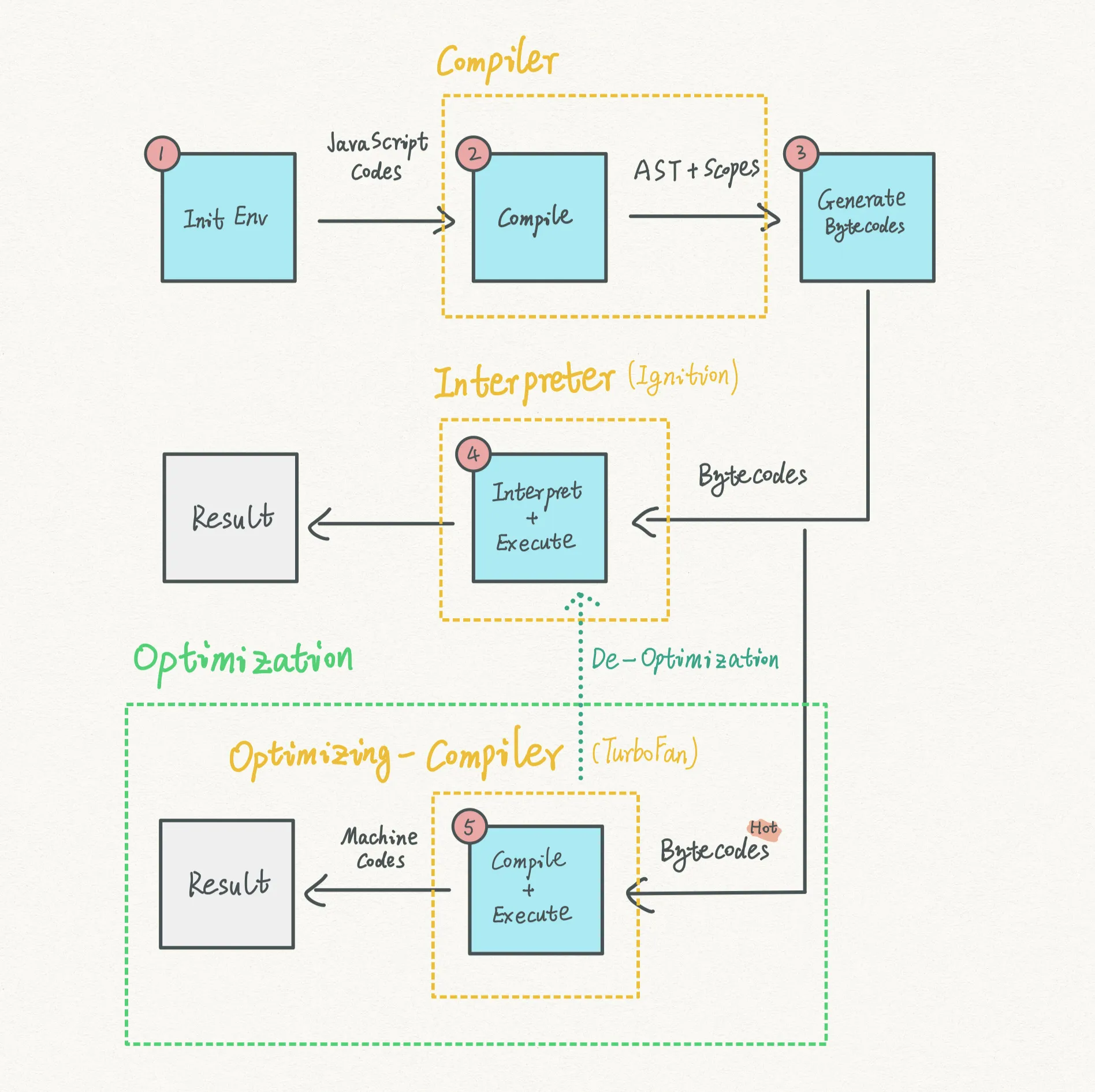
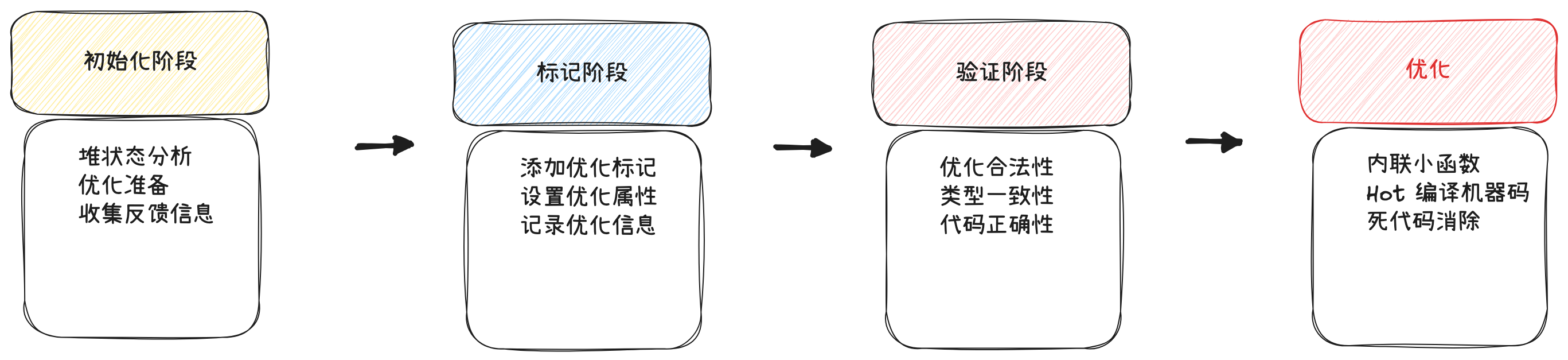
内联优化存在几个针对字节码大小的限制,
💡
小函数内联大小:27字节
单个内联最大字节码:460字节
累计内联上限:920字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
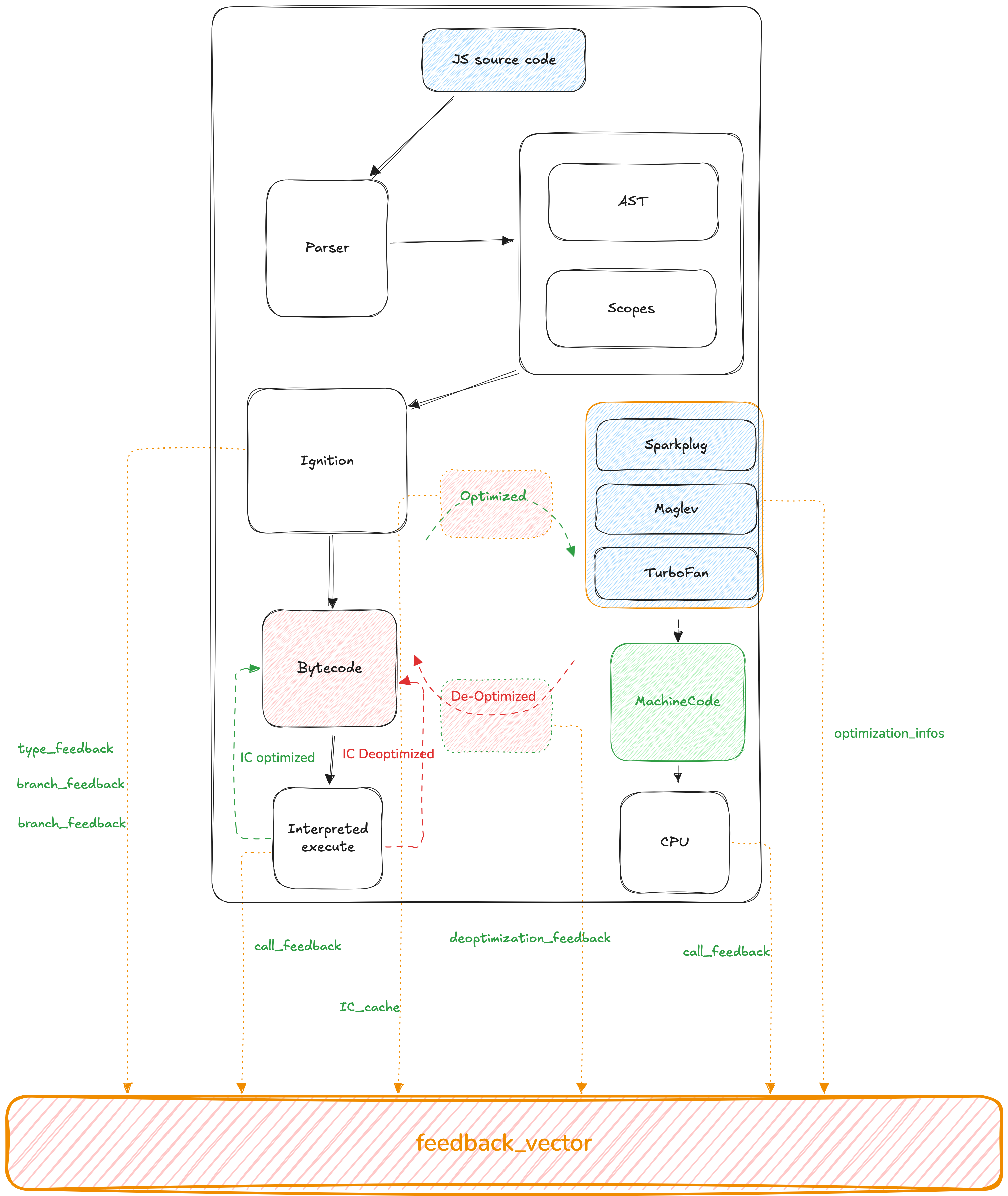
// file : src/flags/flag-definitions.h DEFINE_INT(max_inlined_bytecode_size, 460, "maximum size of bytecode for a single inlining") DEFINE_INT(max_inlined_bytecode_size_cumulative, 920, "maximum cumulative size of bytecode considered for inlining") DEFINE_INT(max_inlined_bytecode_size_absolute, 4600, "maximum absolute size of bytecode considered for inlining") DEFINE_FLOAT( reserve_inline_budget_scale_factor, 1.2, "scale factor of bytecode size used to calculate the inlining budget") DEFINE_INT(max_inlined_bytecode_size_small, 27, "maximum size of bytecode considered for small function inlining") DEFINE_INT(max_optimized_bytecode_size, 60 * KB, "maximum bytecode size to " "be considered for turbofan optimization; too high values may cause " "the compiler to hit (release) assertions") DEFINE_FLOAT(min_inlining_frequency, 0.15, "minimum frequency for inlining") DEFINE_BOOL(polymorphic_inlining, true, "polymorphic inlining")
if (V8_UNLIKELY(v8_flags.always_osr)) { TryRequestOsrAtNextOpportunity(isolate_, function); // Continue below and do a normal optimized compile as well. }
// OSR kicks in only once we've previously decided to tier up, but we are // still in a lower-tier frame (this implies a long-running loop). // 需要优化:但是优先级不够的,提供优化:大循环 TryIncrementOsrUrgency(isolate_, function); return; }
OptimizationDecision d = ShouldOptimize(function->feedback_vector(), current_code_kind); // We might be stuck in a baseline frame that wants to tier up to Maglev, but // is in a loop, and can't OSR, because Maglev doesn't have OSR. Allow it to // skip over Maglev by re-checking ShouldOptimize as if we were in Maglev. if (V8_UNLIKELY(!isolate_->EfficiencyModeEnabledForTiering() && !maglev_osr && d.should_optimize() && d.code_kind == CodeKind::MAGLEV)) { bool is_marked_for_maglev_optimization = existing_request == CodeKind::MAGLEV || (available_kinds & CodeKindFlag::MAGLEV); // 优化第二级:Maglev 优化检查进入 if (is_marked_for_maglev_optimization) { d = ShouldOptimize(function->feedback_vector(), CodeKind::MAGLEV); } }
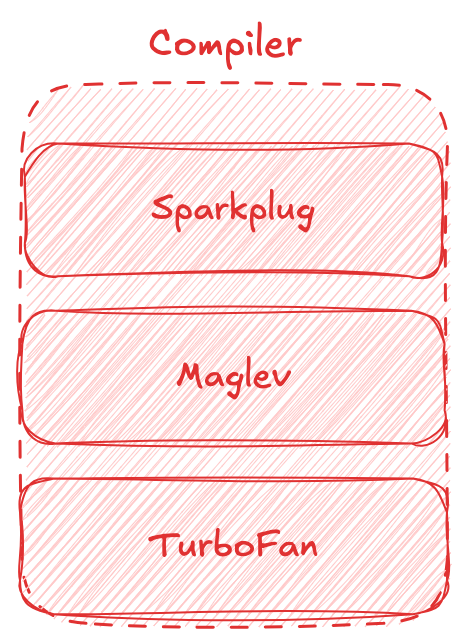
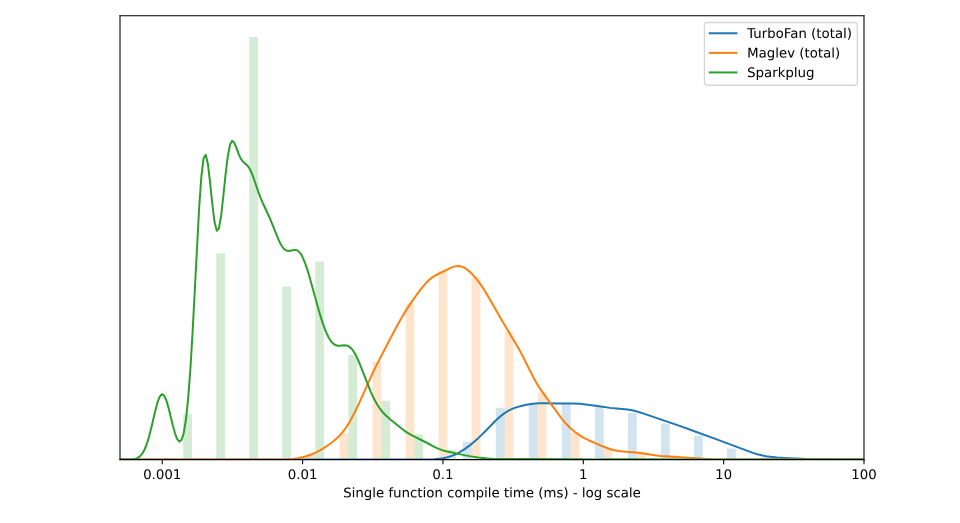
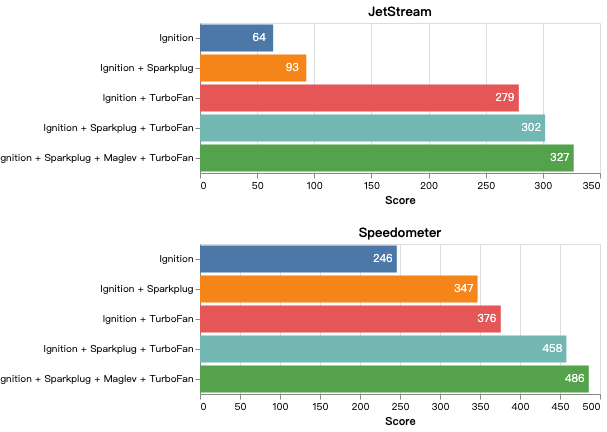
// 进入终极优化: turboFan if (d.should_optimize()) Optimize(function, d); }